最开始接触AI绘图的时候是觉得很新奇,对这个不是很懂但觉得这应该是一个划时代的产物,先前两篇AI绘图的博客就是在这个背景下写的。后来一段时间内,因为对我来说没什么应用环境,所以觉得AI绘图相关更像是玩具,媒体的噱头。
直到最近,我业余开始做一些新媒体账号,有了做封面图的需要,于是又开始重新研究AI绘画相关内容。我发现之前自己还是太浮躁了,只是浅尝辄止用了一下,没有去探究深层次的用法,所以我准备开一个Midjourney的学习笔记专辑,一边学习一边复盘。
describe命令(基于图片生成prompt)
describe命令允许用户上传图像并获得四个试图描述图像的文本提示。describe 命令的输出是一组大致描述图像的文本提示。我认为这是很好地学习模仿他人prompt、获取灵感的方式,在实际应用中,我们可能社交平台中看到自己喜欢的美图(不限于AI生成图),我们就可以通过该命令反推prompt。
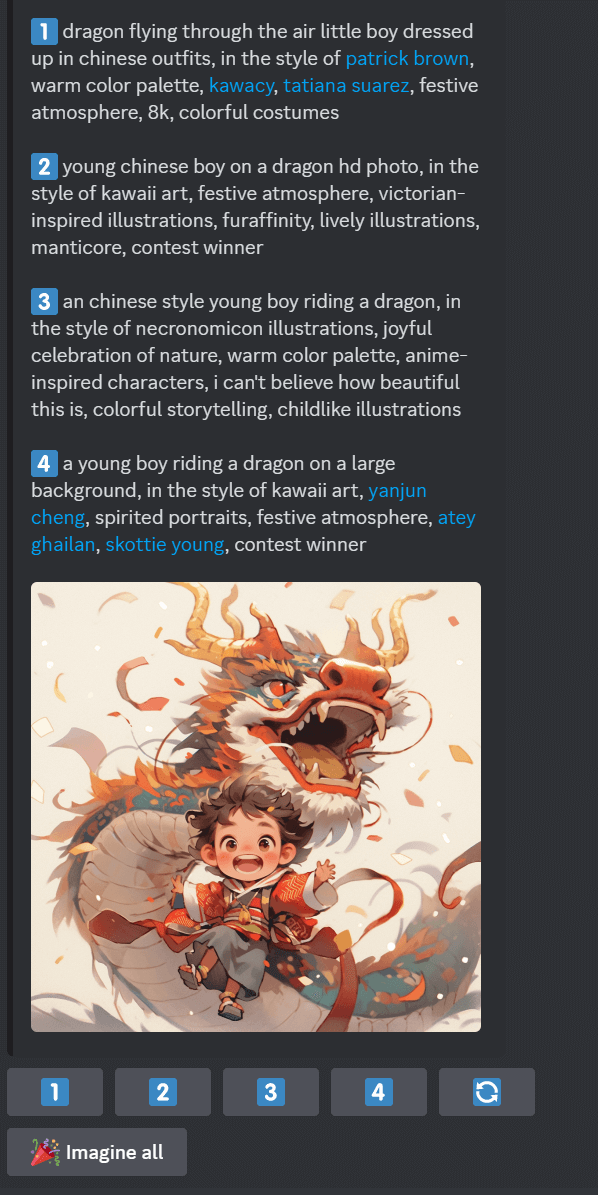
这是我在discord其他频道看到的一张很喜欢的图,当时保存下来之后忘记记录prompt了,这里我就用了describe命令试图复现该图的prompt。

但实际上describe命令也是有局限性的,我记得当时作者的prompt中提到了插画师dao trong le,但反推的4条prompt中并没有以上信息,另外我用语句1生成的4张图片和原图还是存在差异性的,这源于describe没法提供模型版本、–stylize(风格化参数)这类后置参数信息。
这条命令还有进阶用法,可以使用多张图片,生成多个反推的提示词,然后使用chatGPT将多个提示词合并融合,就可以使用新的提示词生成一张由多张图片融合后的图片,这种融合方式相比较于blend命令可以自由搭配提示词,会更灵活一些。
blend命令(混合图片)
输入blend命令后,系统会提示上传两张照片,要添加更多图像,直接输入image3、image4或image5即可,最多能混合5张图片。混合图像的默认纵横比为 1:1,但可以使用可选dimensions字段在方形纵横比 (1:1)、纵向纵横比 (2:3) 或横向纵横比 (3:2) 之间进行选择。
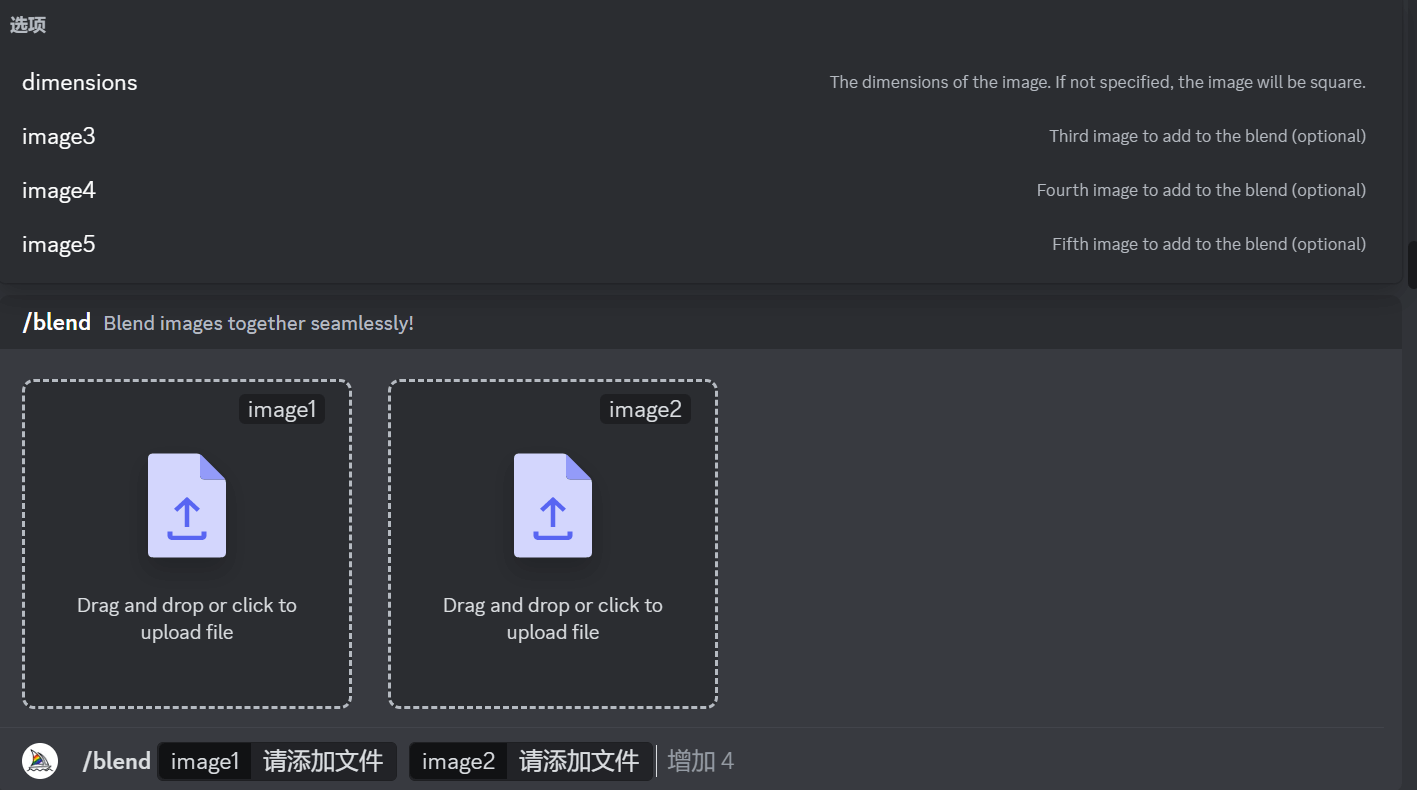
每张图片在混合模式中的权重是平均分配的,实际使用中我觉得还是两张图的混合比较合适,多张图生成图元素就比较混乱了,以下是我之前生成的古风美女和上文提到图片的混合:



从结果来看我还是很满意的,融合效果相当不错,我觉得可以拿去当头像了。blend指令不适用于文本提示,要同时使用文本和图像提示,需要imagine实现,也就是说blend指令功能是包含于imagine中的,且imagine命令支持5个以上图片的混合。实际使用中,当我不需要文本提示,只是混合图片的话,我会用blend命令,因为这可以省去获取图片链接的过程。
imagine命令(文字+图片)
imagine命令应该是midjourney中最常用的命令了,我这里不准备写imagine命令使用提示词文生图的部分,只想写融图和图片+文字的操作方式。
关于融图实际效果和上文提到的blend命令相同,但imagine命令更强大的一点在于不仅支持5张图片以上的混合,还可以在融图命令中加入文字描述部分。
首先我们需要获取图片链接,对于midjourney自身生成的图片,我们只需要右击即可看见相关选项,而本地图片则需要先在聊天框上传之后再右击获取。
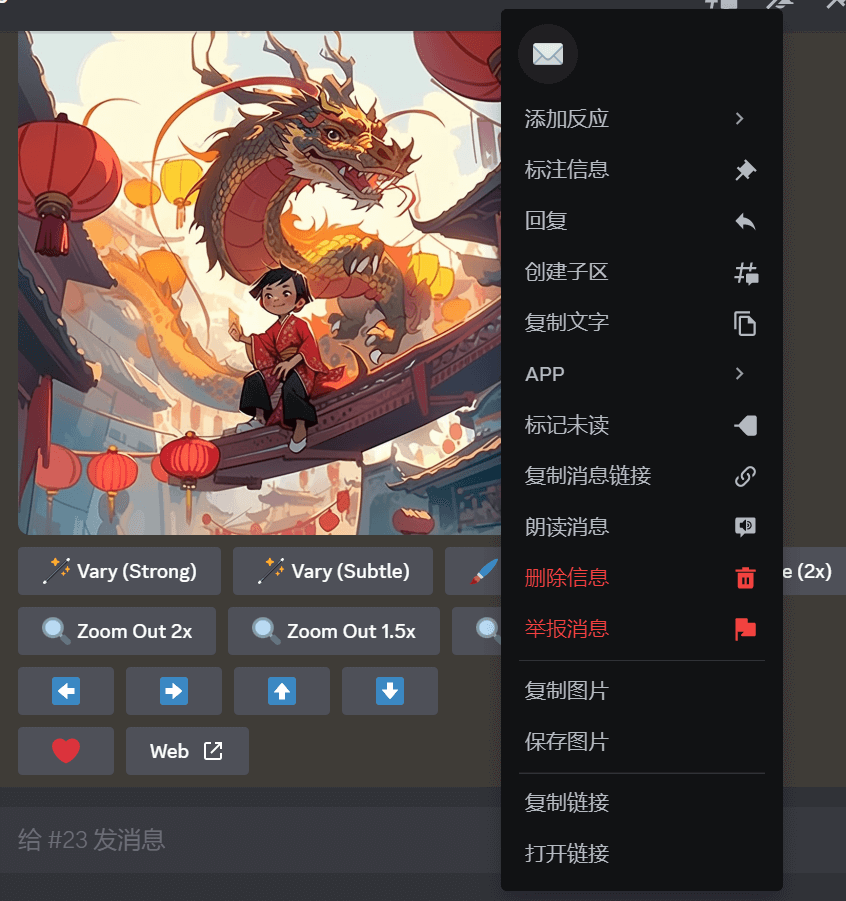
之后在imagine命令的prompt框中输入图片链接,多个图片链接之间用空格隔开,提示词与最后一个图片链接也用空格隔开。
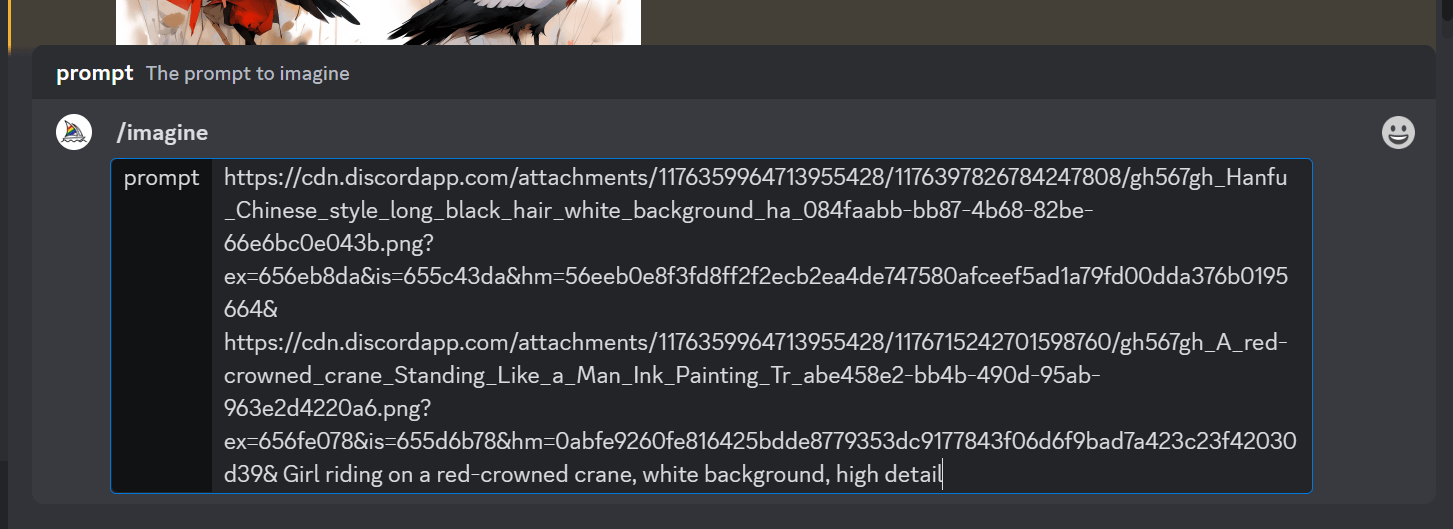
我这里是将之前生成的丹顶鹤与国风美女融合,并加入文字描述“Girl riding on a red-crowned crane, white background, high detail”。


总结
midjourney图生图功能十分强大,相关教程网上也是数不胜数,我这里并不是当教程写的,而是作为我自己的学习笔记,在博客上记录一遍,巩固印象。








评论 (0)