业务背景
云监控的业务背景要从企业上云开始说起,企业上云是指企业可通过网络便捷地按需使用资源(包括计算资源、存储资源、应用软件、服务及网络等),且高度可扩展、灵活易管理的业务模式,具有大规模、虚拟化、高可靠及弹性配置等属性。
而系统服务上云之后势必会带来一些挑战,随着运维对象种类和数量的增加,各个服务版本快速迭代,各类业务规模不断膨胀,同时监控的场景也在不断的发生变化,线上故障随时可能发生,如何保证线上服务稳定运行,同时提升运维效率成了需要思考的问题,如此监控平台应运而生。
我平时查资料还发现另一种监控平台,监控某产品使用数据,比如点击率、转化率、流量等等,这类监控平台偏向于运营方面,而我这里想聊的是偏向运维方面,两者的使用大相径庭,不能混为一谈。但我细想了一下,两者也有可以互相借鉴的地方,比如数据展示方面。
业务架构
参考了几个开源的监控系统zabbix、Prometheus、Open-falcon,然后玩了一下腾讯和阿里的云监控,我把监控平台的核心业务流程抽象为以下几个步骤,如下图所示:
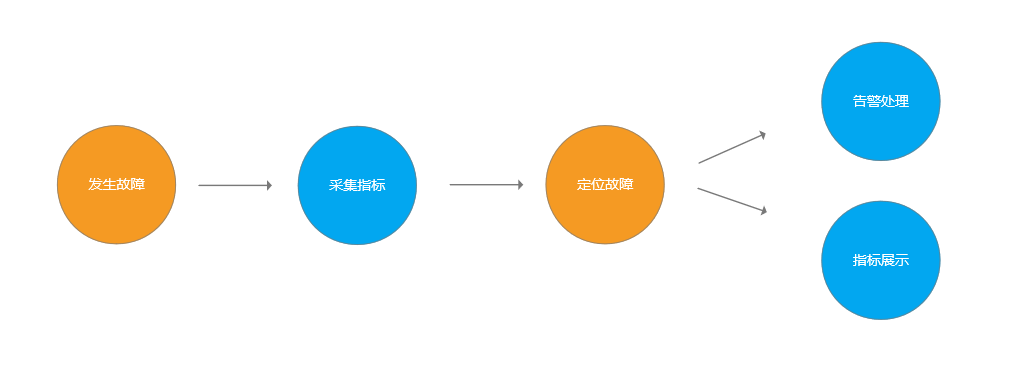
我这里是简单拆解,所以就选了主干流程上的核心功能进行说明。
一个完整的监控平台功能远远不仅于此,功能还涉及:
- 对服务,系统,平台的运行状态实时监控。
- 收集服务,系统,平台的运行信息。
- 通过收集信息的分析结果,预知存在的故障风险,并采取行动。
- 根据对风险的评估,进行故障预警。
- 一旦发生故障,第一时间发出告警信息。
- 通过监控数据,定位故障,协助生成解决方案。
- 最终保证系统持续、稳定、安全运行。
- 监控数据可视化,便于统计,按照一定周期导出、归档,用于数据分析和问题复盘。
为什么要有这么多功能,其实很简单,从监控两字即可分析出来。“监”即为“监”视,需要对平台所涉及的硬件资源以及软件资源进行7*24小时的无间断监视,获取其运行信息,不断进行异常检测。
“控”即为管“控”,在检测到异常时可以进行及时处理,采取对应的控制措施,如发出告警叫醒运维人员进行解决或者是执行预定义的自愈措施,进行快速恢复等。
功能详解
在核心业务流程中,试选取指标采集、指标展示、告警处理功能进行详细说明。
指标采集
指标采集是监控平台的基础,后续各个服务都需要采集到的监控数据来处理对应的业务流程。
采集的指标一般分为以下几类,具体的分类详情要按照实际业务进行适当调整,这里给出的仅是通用的分类方式。
1、基础设施层:
-环境动力:暖通系统(如空调、新风系统、机房环境、漏水等)、电力系统(如配电柜、UPS、ATS等)、安防系统(如防雷、消防、门禁等)等
-网络设备:路由器、二三层网络交换机、多层交换机、负载均衡设备等
-安全设备:防火墙、入侵检测、防病毒、加密机等
2、服务器层:
-虚拟化:虚拟网络资源、虚拟主机、虚拟存储资源等
-存储设备:磁盘阵列、虚拟带库、物理磁带库、SAN、NAS等
-服务器:大中小型机、X86服务器
3、系统软件层:
-操作系统:AIX、LINUX、WINDOWS等
-数据库:ORACLE、DB2、SQL SERVER、MYSQL等
-中间件:WEBSPHERE、WEBLOGIC、MQ、IHS、TOMCAT、AD、REDIS等
-其它系统软件:备份软件
4、应用服务层:
-服务可用性:服务状态、日志刷新、端口监听、网络连通性等
-应用交易:交易整体情况、应用性能(重要交易或整个节点的交易量、耗时、成功率、响应率)、开业情况、批量交易状态等
关于采集器,开源的监控方案中已经有比较成熟的数据采集器了,如TICK技术体系中的Telegraf采集器,或者Prometheus技术体系中exporter采集器。基本覆盖了常见的机器、应用服务数据采集,包括中间件等,同时也可以根据自身的业务特性进行定制开发。
指标展示
对于监控平台来说需要有个信息丰满、覆盖全面的平台全景监控大盘。 用户可以更具自身业务需要进行自定义。另外对于机房、机架、服务器、集群、服务实例、中间件都应该有对应的运行趋势数据展示。
监控采集的大量的数据,除了用于告警,用户不可能逐条查看,用户查看监控数据最主要的途径就是绘制监控图表。绘图能力,非常依赖数据储存,一般有实时信息图和历史信息图两种。
当故障发生时,必定会导致某些数据的变化,而这些数据的变化在运行趋势图中必定会有所体现。研发人员以及运维人员可以结合对应的趋势图来判断异常的可能原因。
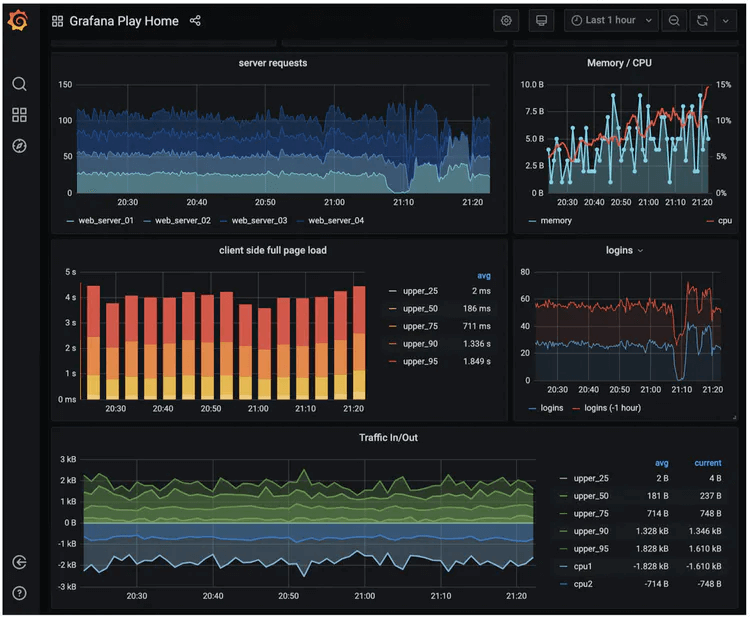
采集来的指标数据可以在指标仪表板上显示,我们可以借助开源的组件满足我们的需求,Grafana 是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。
下图显示了一些指标,服务器的请求数量、内存/CPU 利用率、页面加载时间、流量和登录信息。
告警处理
准确判定异常情况,设置灵活的告警策略以及丰富的告警渠道,是最终体现监控系统能力的最直接的方式。
告警判定,获取告警的规则配置和采集到的指标数据,来判断是否需要告警,并通知相应的告警渠道来出发告警。
策略配置,对于告警策略,要尽量灵活,结合多 tag 的数据模型,可以定制出非常灵活的告警策略。另外,对于告警级别,告警合并,告警抑制,告警恢复,告警升级的支持,在设计阶段都要考虑在内。
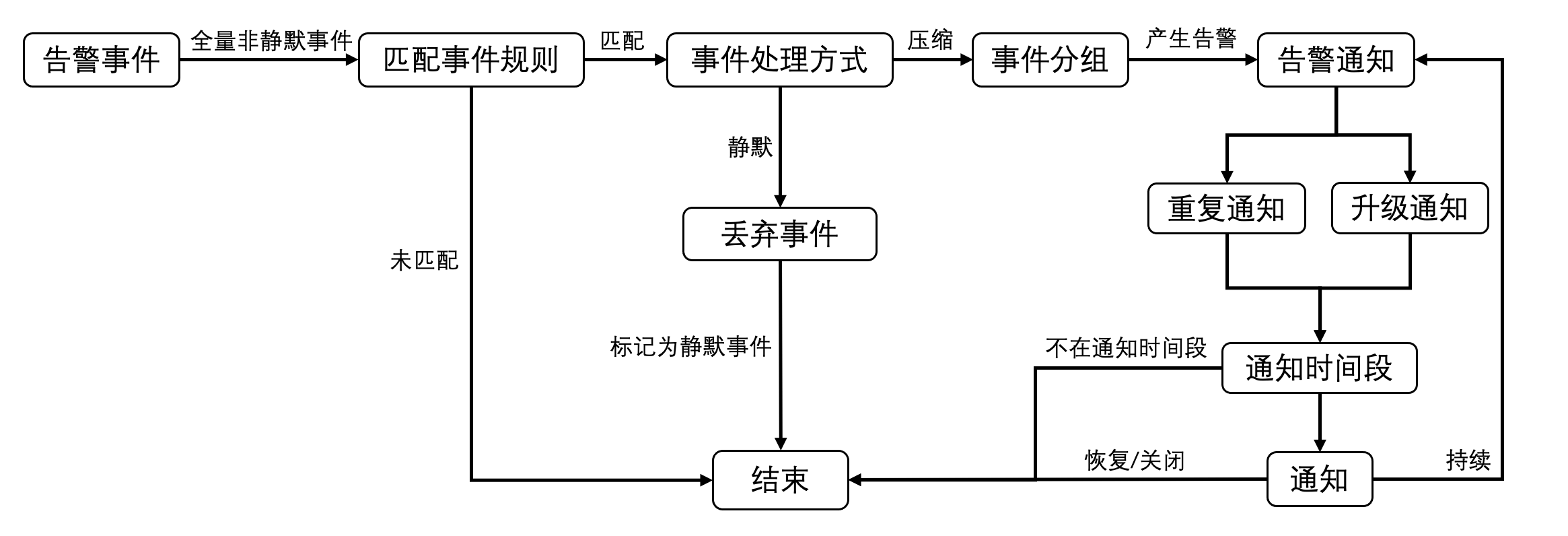
近期在设计告警订阅功能优化的时候,阿里云监控实时服务ARMS的新版告警管理找到了思路,给云上各种资源打标签,提升灵活易用的多维度资源管理能力,精准分发告警。
告警渠道,即发送告警的通道,常见的有邮件,IM(钉钉/企业微信等),短信,电话等,还要考虑 web hook 的支持,便于对接其他的系统。
告警处理分析模块通过记录和分析告警处理的过程,可以对单个告警进行复盘或者对过去一段时间内的告警进行处理分析,找出告警处理过程中的薄弱点,优化告警处理流程,提高处理效率。
与Grafana、Loki、Prometheus结合可以通过Grafana大盘实时查看已处理和未处理的告警,实现通过一个大盘全盘掌握系统告警处理状态。
总结
监控系统对 IT 系统运维意义重大,从状态监控到收集/分析数据,到故障告警,以及问题解决,最后归档报表,协助运维复盘。我也只是简单拆分了一下大概有哪些功能点,有时间会针对这些功能进行详细说明。
参考文档
【1】prometheus从入门到精通
【2】应用实时监控服务ARMS产品说明文档——阿里云
【3】监控体系建设(二):监控指标——腾讯云
【4】如何设计一个可扩展的指标监控和告警系统——博客园
【5】如何设计一个监控平台——掘金








评论 (0)