
最近在做基于知识图谱的物联网应用系统,随着对知识图谱应用的逐步了解,我意识到如果把知识图谱应用到网络运维上,或许能够解决网络领域典型场景下的智能化运维问题。
本科时期我的毕业论文就是知识图谱对于湿地生态系统物种数量计算的相关运用,实际上当时只是做了几个算法demo,根本没有落地,属于理论上的设计。
我查了大量的资料,调研到知识图谱在运维领域的运用也就是这几年的事情,已经产生了一些成熟的方案,正好之前监控项目组的产品找到我,让我帮着想一想监控的三期方案,我想基于运维知识图谱做 AIOps ,是一个非常好的优化方向。
二期现状
定制拓扑监控是二期的特色功能,将告警匹配监控实例信息,并绘制网络拓扑图,就可以清晰地在网络拓扑图上看到具体是哪台设备产生了告警。在实际运维场景中,发生告警时,值班室内的监控大屏上某设备开始闪烁,并弹出相应的告警信息,根据后台的人员值班表,在大屏右上角展示处理告警的人员,运维人员排查告警原因,待告警恢复后,填写运维工单。
这在大多数时候能使运维人员快速响应告警,可还是免不了“头痛医头,脚痛医脚”的情况,告警发生是“果”,比如服务崩溃,但是导致告警发生的“因”可能有很多,可能是服务自身Bug导致的内存溢出,可能是服务器CPU被打满,可能是依赖的服务有问题。
因此根因追溯是辅助研发以及运维人员进行故障定位的重要手段和措施。只有快速而准确的进行故障根因定位,才能将故障造成的损失降到最低。
除此之外,在和运维工程师不断的交流及对用户场景的调研发现,绝大多数运维工程师及其团队都有一套应对告警的解决方案,经过大量运维实践案例的积累,知识库也随之丰富,目前用户也有将解决方案和实时告警关联起来的需求。
知识图谱下的智能运维
为了满足故障定位、根因分析、知识管理的需求,我们需要通梳理出两张知识图谱:信息资源知识图谱、告警知识图谱,结合每次出现故障的案例,通过不断地提炼和丰富知识图谱,使其分析故障能力不断提升。
故障定位和根因分析
通过通过构建和拓展信息资源知识图谱、告警知识图谱达到一定程度以后,图谱就可以通过一些算法找到关键事件来进行系统自主故障定位,实现故障下探,挖掘平台真正的出血点。
信息资源知识图谱构建
对于信息资源知识图谱,我们可以从 CMDB 数据、调用链数据和物理设备网络连接数据构建,监控运维的对象主要涉及机房、机器、各类设备以及应用服务等多种资源对象,关系包括 constitute(构成)、call (调用)、logical(逻辑连接)、cluster(汇聚)、ship(承载)、host(宿主)、connect(物理连接)等。
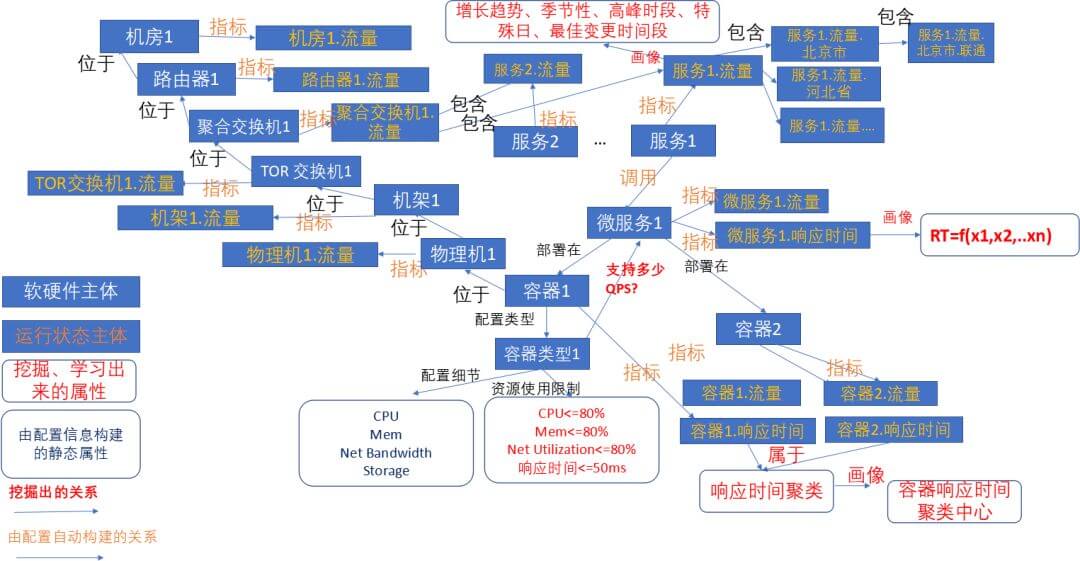
无论是监控对象是设施对象还是应用对象,它都是一种资源信息。需要通过抽象的资源模型进行支撑以及扩展,我们可以设计如下的资源模型:

知识图谱本体建模时,应根据实际业务需要设计本体属性,这将在未来运维工作中不断完善,丰富全面的属性集是要能覆盖运维分析需求的。
告警知识图谱构建
对于告警知识图谱,我们可以从历史告警数据、指标仓库、日志信息等获得知识来源,当我们从不同来源、不同结构的数据源中获取知识语料后,就要进行整理工作。
那么我们首先要做的就是告警分类,利用自然语言分析算法在处理历史告警数据的时候正确率并不高,例如各类资源的利用率就常常被分类错误,因此采取人工分类效果可能会更好。
这部分的工作具有比较深远的意义,建立统一的告警分类、指标仓库有助于未来跨区域部门的业务对接,当所有人使用同一套标准的时候,将大大提升对接效率,而不用再耗费时间对齐告警定义。项目二期已经划分了告警分类,未来就可以直接将告警分类作为因果节点使用。
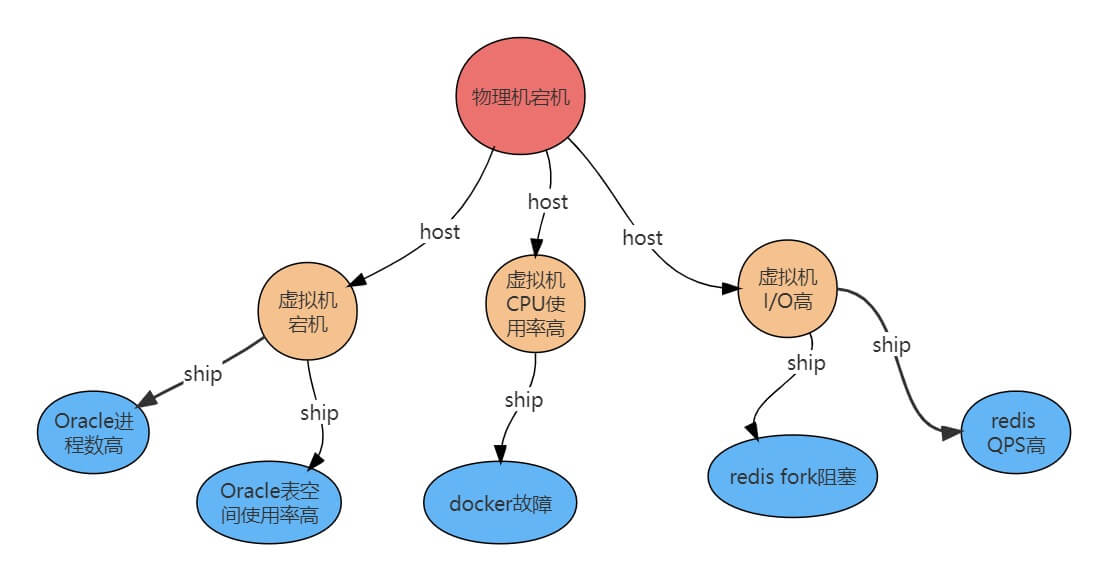
根据告警分类,已将每一条告警记录归类为一种告警类型(告警类型:物理机- xx 告警、虚拟机-xx 告警、软件-xx 告警)。以每条虚拟机告警记录为中心,给定一个告警时间切片(1min、2min 等),寻找每条虚拟机告警时间切片内的相关告警记录(相关告警包括: 该虚拟机隶属的物理机上的告警,同隶属该台物理机上的其他虚拟机上的告警)集合作为一个因果发现样本。

再通过因果算法输出因果边和权重,例如一条因果边,物理机宕机->虚拟机宕机->Docker服务故障,权重为98%,此时我们可以下结论,这些告警大概率存在因果关联。
最后我们根据因果指向和权重,构建出告警知识图谱,部分示例如图:
根因路径分析
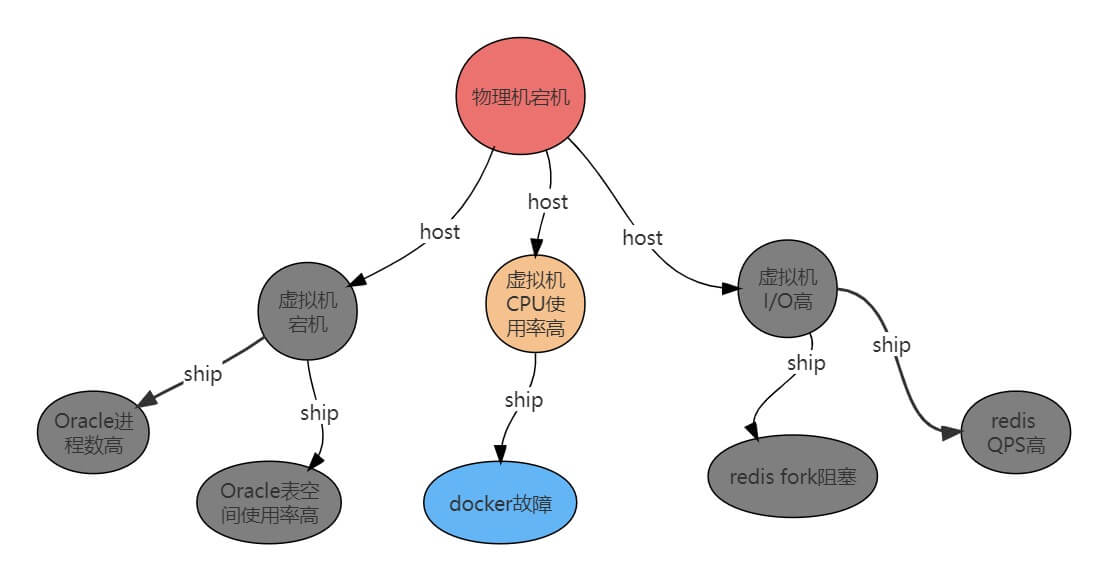
我们将两张知识图谱写入图数据库,以便持久化读取,并对告警进行收敛操作以减轻服务器压力,应对不定时的告警风暴,这是根因分析的前期准备工作。
对于一段时间切片中的某个系统,我们在图数据库中信息资源知识图谱查询该系统下的所有节点构成的子图,经过处理将包含告警信息的节点筛选出来,再结合告警(根因)知识图谱,得到精简后的告警根因图。分析各路径的权重之后,我们便得到了疑似的根因路径,如图:
运维知识库
运维人员常常会面对解决重复相同的问题,如果大多数人问题及解决方案都可以从知识库中方便,快捷的获取就可以避免这种现象发生,从而达到提升运维工作效率,降低IT运维成本的目的。
运维方案的知识来源在结构化(例如:告警、指标等)、半结构化(例如:配置、日志、规范化产品文档)、非结构化(例如:实践手册、故障案例、分享帖子)数据中。这些网络知识来源于support网站的产品文档,运维专家的维护文档,发生告警故障时的现网抓包数据,现网环境的配置文档数据,运维专家的经验沉淀文档或者故障传播知识采集等。
在获得了告警知识图谱之后,我们在每个告警节点上维护运维方案的属性,属性值则为操作手册的跳转链接。如此,在告警产生之后,运维人员便能沿着告警根因路径,一路查看运维方案,解决各式各样的问题。
参考文档
【1】知识图谱可视化技术在美团的实践与探索
【2】苏宁基于 NebulaGraph 构建知识图谱的大规模告警收敛和根因定位实践
【3】NebulaGraph图数据技术应用案例集
【4】苏宁 AI 监控运维保障建设实践






网站常看常新,每次都会有收获。感恩~
@L: 能给您带来收获,我也很高兴